❗ Congestion control의 필요성
TCP 통신시에 sender는 네트워크 환경과 receiver의 역량, 2가지를 고려하여 자신의 flow를 조정해야 한다.
두가지 변수 중에 상황에 따라 상대적으로 더 좋지 않은 변수에 맞춰야한다.
congestion control은 네트워크 환경을 고려하여 통신하는 TCP의 원리이다.
network 환경은 기본적으로 public이다. 누구나 인터넷을 사용할 수 있다. 그래서 아무런 제약없이 인터넷을 사용하도록 해두면 네트워크가 막힐 수 밖에 없다. TCP의 reliable을 보장하는 특성상, 패킷이 유실될 경우 재전송을 하기 때문에 네트워크가 제약없는 상태에서 막히면 막힐 수록 상황은 더욱 악화되기 마련이다. 내가 양보를 해야지 나도 살고 너도 살고 우리가 살게 되는 것이다. 네트워크는 아주 소중한 자원이기 때문에 서로 적절히 양보하며 자원을 사용해야 한다.
그렇다면 congestion control은 어떻게 네트워크 환경을 고려하여 통신을 진행할 수 있을까?
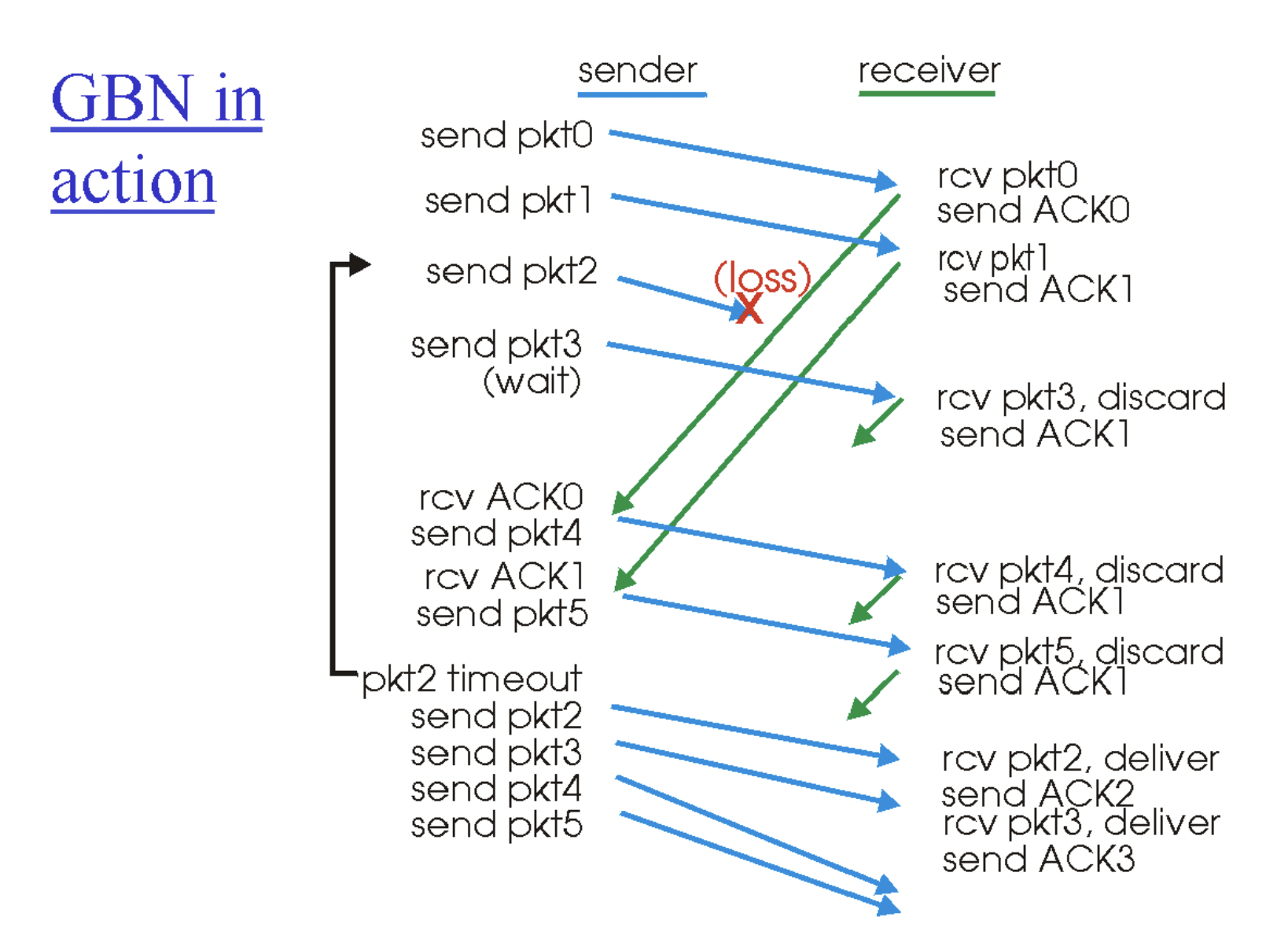
접근할 수 있는 방법은 크게 보면 2가지가 존재한다. 네크워크에서 직접적으로 정보를 받는 방식과 통신하는 노드를 통해 정보를 받는 방식이다. 라우터를 할일이 굉장히 많기 때문에 현실적인 제약으로 네크워크에서 직접적으로 정보를 받는 방식은 구현되지 않고 있다. congestion control은 후자, 그중에서도 노드간의 통신에서 간접적 정보를 통해 판단을 내리는 방식을 채택한다. 간단히 말하면 조금씩 조금씩 보내보다가 괜찮으면 좀 더 보내고 그러다가 유실이 발생하면 window size를 줄이는 방식이다.
❗ congestion control의 원칙과 작동원리
1. slow start
통신의 초기에는 네트워크의 상황이 어떠한지 판단이 불가능하기 때문에 세그먼트 1개 즉 1MMS크기의 window size를 갖고 통신을 시작한다. 1MSS로 시작하여 threshold 값 까지 exponential 하게 증가한다. threshold를 모르는 초기에는 유실이 발생할 때 까지 exponential하게 window size를 늘린다.
MSS(Maximun Segment Size : 세트먼트가 갖을 수 있는 최대크기, 500byte)
2. addtive increase
window size가 threshold를 지나간 시점부터는 linear하게 증가한다.
3. multiplicative decrease
유실이 발생했을 경우 threshold를 window size의 절반으로 떨어뜨린다. 그리고 window size는 유실판단 기준에 따라 달라지게 된다. 유실은 timeout과 3 duplication ack를 받은 경우로 나뉜다. 1) timeout의 경우 정말로 패킷이 유실되어 오지 않은 경우이기 때문에 네트워크 상황이 좋지 않다고 판단하여 window size가 1MSS로 설정된다. 2) 3 duplication ack의 경우는 네트워크 상황이 나쁘지는 않지만 하나의 패킷이 유실된 경우이기 때문에 window size를 threshold값으로 설정하여 바로 linear한 통신을 진행하게 된다.
최적의 threshold값을 찾아 그 언저리 값으로 통신하면 되는거 아니야? 하고 생각할 수 있지만 threshold는 네트워크 상황과 리시버의 환경에 따라 계속해서 변화하기 때문에 congestion control은 변화하는 threshold값을 계속해서 찾아나가는 과정이라고 보는 것이 맞는것 같다.
❗ Is Tcp fair?
TCP는 독립적인 노드들이 자신의 Flow를 조정하는 방식으로 작동하는데, 이것이 과연 모두에게 공평한가에 대한 의문을 가질 수 있다. 만약 네트워크 사용량이 R이라면 n명의 사용자가 있을때 모두 R/n 만큼 사용가능한가 라는 것이다. 직관적인 이해를 조금 힘들 수 있지만 결국 R/n으로 수렴한다고 한다.
'computer science > Network' 카테고리의 다른 글
| [network] wireless 통신과 CSMA/CA 프로토콜 원리 (0) | 2022.11.25 |
|---|---|
| [network] Linked Layer, CSMA / CD 프로토콜의 개념과 동작원리 (0) | 2022.11.25 |
| [network] TCP Connection management와 3way-handshake (0) | 2022.10.28 |
| [network] TCP flow control의 목적과 작동방식 정리 (0) | 2022.10.28 |
| [network] TCP의 신뢰성 확보를 위한 Timeout 한방정리 / Fast Retransmission (0) | 2022.10.27 |